拡張READ/WRITE方式 その1
- 1 COBOLでA−VX/RDBを扱う
-
A−VXのCOBOLからA−VX/RDB上のデータを読み書きする方法として、の2種類があります。一つは拡張READ/WRITE方式(拡張DMLとかCOBOL−DML、COBOL85 DMLともいう)、もう一つはSQL方式(SQL−DMLともいう)です。
拡張READ/WRITE方式は、従来のファイルと同じようにOPEN→READ→WRITE→CLOSEといった命令でRDBのデータにアクセスする方式です。基本はファイルと同じ命令ですが、いくつかRDBに対応した命令が追加されています。
SQL方式は、皆さんなじみのあるあのSQL文を使います。埋込みSQLです。
しかし、SQL86の規格ベースですし、前に書いた通りDMLのみ使用でき、DMLなら何でも使用できるわけではなく、SQLEXTENSIONの説明書に書かれているもののみです。まず、拡張READ/WRITE方式から説明していくことにします。
- 2 拡張READ/WRITE方式の特徴
-
NECの公式の説明書には、拡張DMLとかCOBOL−DML、COBOL85 DMLとかいろいろな用語で書かれていますが、皆同じです。(用語は統一してほしいよ・・・)
拡張READ/WRITE方式の特徴は次の通りです。
- 従来のファイルシステムと同じようにコーディングできる
- 従来のファイルシステムからRDBシステムへのプログラムの移行が簡単(ほぼ修正無しで移行できる)
- 従来のファイルシステムとほぼ同様の保守運用方法となる
1つめの「従来のファイルシステムと同じようにコーディングできる」ですが、最初に書いたように、OPEN/CLOSEやREAD、WRITE、REWRITE、DELETEといった命令を使ってデータベースに対して読み書きを行います。つまり基本表や仮想表(つまりテーブルやビュー)に対して、普通のファイルのようにアクセスすることができるということです。
基本表(テーブルのことね)を順編成ファイルのように順番にREAD/WRITEしていったり、相対編成ファイルや索引順編成ファイルのようにキーを使ってREAD/WRITEしていくことができます。READ 〜 AT END 〜とかWRITE 〜 INVALID KEY 〜なんて書き方ができます。
何がいいかというと、「普通のファイルのアクセスならノウハウが蓄積されているでしょう」とか、「このデータは普通のファイルに入っているからREAD/WRITE、これはデータベースだからSQLで」とか分けて考えなくていいとか、「このデータは順アクセスしかしないから順編成、このデータは検索するからこいつをキーにして・・」とかシステム設計時にファイル編成を考えなくてもいいとか、「ファイルからデータベースにシステム構成を変えてもファイル時代のプログラムがそのまま何の変更もなく使える」(このおかげで、年季の入ったプログラムが今だに現役で使えてたり・・・)とか、いろいろな理由があります。
普通のファイルにアクセスする命令だけで一通りのことができるので、普通の人はREAD/WRITEなどがあれば満足するのですが、中には「RDBなんだからREAD/WRITEだけだと嫌だ」という人もいます。そういう人の為にSELECT、SCRATCH、COMMIT、ROLLBACKといった命令が追加されています。
2つめの「従来のファイルシステムからRDBシステムへの業務プログラムの移行が簡単」ですが、従来のファイルシステムからRDBにデータを移行したときに、業務プログラムの修正/変更がほとんど必要ないということです。後で少し説明しますが、これは本当に簡単です。利点でもありますが、一方そこまでの対応で終わったままのシステムもたくさんみられる原因ともなりました。
3つめについては、結局RDBファイルの実体が複数索引順編成ファイルであるので、基本的には「RDBの保守運用方法は複数索引順編成ファイルの保守運用方法と同じ」ということになります。このためそれほどRDBを知らない人であっても、従来のファイルシステムを知っていれば、A−VX/RDBもそのまま保守運用できるということになります。これは利点でもある一方、RDBがファイルに引きずられているので、A−VXのファイルシステムをを知らない人はA−VX/RDBを十分使いこなせない原因ともなっています。
具体的には、RDBファイルも複数索引順編成ファイルと同様にファイル再編成が必要となる、などです。 - 3 ファイル編成
-
表にはファイル編成という概念がありません。しかし、従来互換の為に、表をファイルとして扱うことができるようになっています。
プログラム、特にCOBOLから拡張READ/WRITEアクセスするときには、表を順編成、相対編成、索引順編成、(複数)索引順編成のファイルとして扱います。
従来互換としてではなく、RDBとして使用する場合は、RDBとしての機能をフルに使用できます。
ファイル編成 概 要 順編成 表を順編成として扱う 相対編成 表を相対編成として扱う 索引順編成/複数索引順編成 表を索引順編成/複数索引順編成として扱う RDBファイル 表をRDBファイルとして扱う プログラム上で、表を順編成ファイルと指定して扱うと、データファイルに直接アクセスすることができます。この場合、表のデータを格納順に読み書きすることができます。
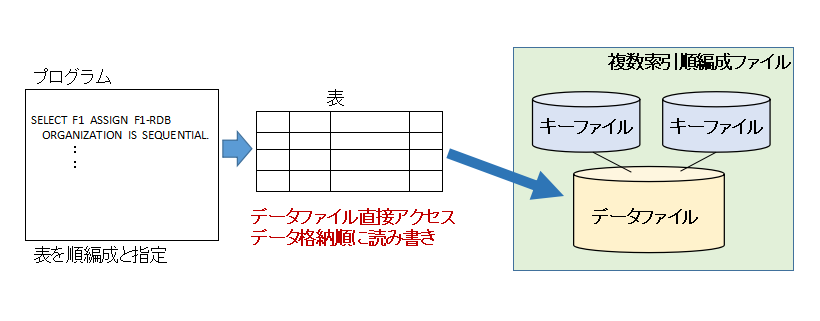
プログラム上で、表を相対編成ファイルと指定して扱うと、データファイルを直接アクセスすることができ、相対キーアクセスができます。
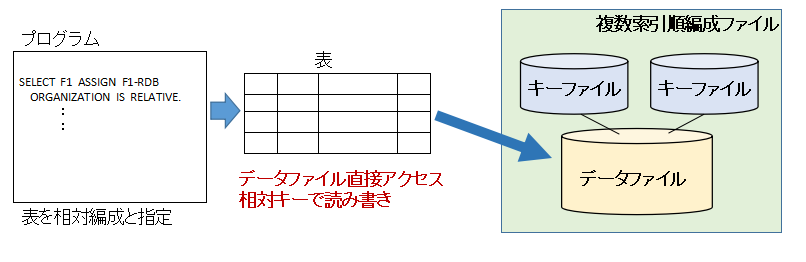
一般的なRDBで、データを格納順に順番に読み込んだり、データの格納位置を直接指定して読み書きすることはできないと思うので、この辺りはA−VXのRDBの特徴的な部分だと思います。(正確には当時のオフコンやメインフレームのRDBではこのような動作ができるようになっています。オープン系のRDBはこのようなことはできないはず。)
(複数)索引順編成ファイルの場合、仕様上はデータファイルを直接アクセスすることはできません。ここが(複数)索引順編成ファイルを直接ファイルとして使用する場合とRDBファイルとして扱う場合の違いとなります。
プログラム上で、表を(複数)索引順編成ファイルと指定して扱うと、キーファイル経由でデータにアクセスすることができます。
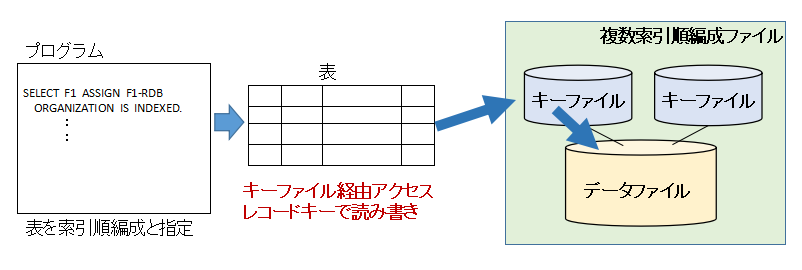
表を順編成として扱ったり、相対編成として扱ったり、索引順編成として扱うのは、互換性を持たせるためです。先に説明したように、今までファイルを扱っていたプログラムを基本修正無しで、RDBを扱えるようにするために、そのような仕組みになっています。
いちいち「データファイルを直接アクセス」「キーファイル経由でデータにアクセス」と書いていますが、ここが重要だからです。一般的なRDBではこんな動作はしないでしょう。データファイルを直接アクセスする場合とキーファイル経由でデータにアクセスする場合の違いは後で説明します。
- 4 処理モード
-
表を順編成ファイルと指定した場合、次の四種類の処理モードを使用できます。
処理モード 概 要 入力処理モード ファイルの始めからレコードを読み込む 出力処理モード ファイルの始めからレコードが書き出される 更新処理モード 先頭から順番に読み込み、そのレコードのデータを変更して同じ場所に書き込むことや削除することができる。 追加処理モード 現在のファイルの最後のレコードの次のレコードから書き込んでいく 表を相対編成ファイルと指定した場合、次の三種類の処理モードを使用できます。
処理モード 概 要 入力処理モード ファイル内のレコードの読み込みだけが許される 出力処理モード ファイルの始めからレコードが書き出される 更新処理モード ファイル内のレコードを読み込んだり、ファイル内にレコードを追加したり、またレコードの置換または削除をすることができる 表を索引順編成ファイルと指定した場合、次の三種類の処理モードを使用できます。RDBとして使う場合もこれです。
処理モード 概 要 入力処理モード ファイル内のレコードの読み込みだけが許される 出力処理モード ファイルの始めからレコードが書き出される 更新処理モード ファイル内のレコードを読み込んだり、ファイル内にレコードを追加したり、またレコードの置換または削除をすることができる A−VX/RDBのデータは、複数索引順編成ファイルの影響が強いので、ファイルの始め/ファイル先頭位置のデータとか、ファイルの終わり/ファイル最後の位置のデータといった概念があります。普通のRDBのデータにファイルの先頭位置のデータとか最後位置のデータといった概念はないと思います。
- 5 アクセスモード
-
表を順編成ファイルと指定した場合、次の呼び出し方式が行えます。
アクセスモード 概 要 順呼び出し方式 データファイルの先頭レコードから順次呼び出すことができる 表を相対編成ファイルと指定した場合、次の三種類の呼び出し方式が行えます。
アクセスモード 概 要 順呼び出し方式 データファイルの先頭レコードから順次呼び出すことができる。順編成ファイルと同じ 乱呼び出し方式 相対レコード番号の値によって目的のレコードを参照、更新、削除、追加する 動的呼び出し方式 相対レコード番号の値によって目的のレコードを乱アクセスしたり、位置づけされたレコードから順アクセスすることができる 表を索引順編成ファイルと指定した場合、次の三種類の呼び出し方式が行えます。本格的にRDBとして使用する場合もこれになります。
アクセスモード 概 要 順呼び出し方式 レコードキーの昇順・降順に順次呼び出すことができます。同一レコードキーがあるときは、レコードの発生順に利用者に渡される 乱呼び出し方式 レコードキーの値によって目的のレコードを参照、更新、削除、追加する 動的呼び出し方式 レコードキーの値によって目的のレコードを乱アクセスしたり、位置づけされたレコードからレコードキーの昇順・降順にしたがって順アクセスすることができる - 6 COBOLの命令
-
ファイルのアクセスからそのままRDBファイルに移行した場合は、同じ命令をそのまま使用できます。
- OPEN
- START
- READ
- WRITE
- REWRITE
- DELETE
- CLOSE
- USE
例えば、表を順編成ファイルとして扱う場合は、通常の順編成ファイルと同じようにOPEN/READ/WRITE/REWRITE/CLOSEといった命令が使用できます。命令の書き方、使い方も順編成ファイルのときと同じです。
このように従来のファイルの互換として使用する場合は、順編成/相対編成/(複数)索引順編成ファイルのそれぞれの命令をそのまま使用できます。実際、RDBにしたけど、使っている命令は今まで通りこれだけというところも多いです。
しかしせっかくRDBにしたのにこれでは物足りないということもあるでしょう。そのようなときのために、既存の命令が強化されたり、命令が追加されたりしています。
命令の強化の例としては、READ文でレコードを逆順(PRIOR句)でも読み込めるようになっています。
- レコードの逆順読み:READ PRIOR
- 現在指示子による更新:REWRITE CURRENT
- 順編成ファイル指定時のSTART FIRST、START LAST
- 順編成ファイル指定時のDELETE
追加された命令は次の通りです。
- SELECT
- SCRATCH
- COMMIT
- ROLLBACK
SELECTは、SQLのSELECT文とは異なります。レコード選択条件を満足するレコードを表から選択抽出し、部分集合ファイルを作成する命令です。
SELECT ファイル名 WHERE レコード選択式 [ ; COUNT IN 一意名-1 ] [ ; ORDER BY { ASCENDING | DESCENDING } データ名-1 [ , データ名-2 ]・・・ [ BY { ASCENDING | DESCENDING } データ名-1 [ , データ名-2 ]・・・ ] (例) SELECT F1 WHERE ( SURYO NOT < 10 ) AND ( SURYO > 20 ) ORDER BY ASCENDING KEY SURYO.SCRATCHは、SELECTと対になるもので、SELECTで作成した部分集合ファイルを解放します。
SCRATCH ファイル名 (例) SCRATCH F1.
COMMITとROLLBACKはトランザクション関連の命令です。これは一般的なRDBのCOMMIT/ROLLBACKと同じような使い方です。


