拡張READ/WRITE方式 その2
- 1 従来ファイルシステムからの移行性
-
データをファイルからRDBに移行したときに、業務プログラムをほとんど修正する必要がないということは、A−VX/RDBの最大の特徴の1つです。あるいはまったく修正することなく業務プログラムを動かすことができます。
RDBが登場する前は従来のファイル(順編成ファイル、相対編成ファイル、索引順編成ファイル etc.)を使ってシステムが組まれていました。昔はRDBを使わないシステムが大量にあったわけです。
RDBが登場した当時、いかに簡単にファイルを使ったシステムからRDBを使ったシステムに変更するか、は重要でした。通常ファイルからRDBに変更した場合は、READ/WRITEでファイルアクセスしているプログラムをSQLを使用するプログラムに変更する必要があります。これは単にREAD文をSQLのSELECTに、WRITE文をINSERTに直せばいいというわけではなく、ロジック自体も大きく変更する必要があります。
A−VX/RDBの場合はそれが必要ありません。ほとんど必要ないといっても「何か所かは直す必要があるんでしょ?」という人もいるかもしれませんが、そんなことはありません。具体的には1か所、「MSDxxx」を「RDB」と直すだけです。
例 (1) SELECT MST-F ASSIGN TO OLDFILE-MSD000 ↓ SELECT MST-F ASSIGN TO OLDFILE-RDB (2) SELECT TOKUI-F ASSIGN TO TOKUI-MSD002 ↓ SELECT TOKUI-F ASSIGN TO TOKUI-RDB
[リレーショナル型データベース(2009年11月版)−第2部 設計編−第4章 RDBへの移行]より要するに、使用するデータを”ファイル”から”RDB”を使用するように変更するだけです。
こんなプログラムがあったとしても、修正するところは1か所だけ。
000010 IDENTIFICATION DIVISION. 000020************************************************************ 000030** SAMPLE PROGRAM ** 000040** ファイルの内容を画面に出力する ** 000050************************************************************ 000060 PROGRAM-ID. YAMAGU. 000070* 000080 ENVIRONMENT DIVISION. 000090 INPUT-OUTPUT SECTION. 000100 FILE-CONTROL. 000110 SELECT INFILE1 ASSIGN TO FILE01-MSD 000120 ORGANIZATION IS SEQUENTIAL 000130 FILE STATUS WFSTS1. 000140 I-O-CONTROL. 000150 APPLY EXCLUSIVE-MODE ON INFILE1. 000160* 000170 DATA DIVISION. 000180 FILE SECTION. 000190 FD INFILE1 000200 BLOCK CONTAINS 256 CHARACTERS 000210 LABEL RECORD IS STANDARD 000220 VALUE OF IDENTIFICATION IS "FILE01". 000230 01 INREC. 000240 02 A1 PIC X(80). 000250 02 A2 PIC X(176). 000260* 000270 WORKING-STORAGE SECTION. 000280 01 WFSTS1 PIC X(02). 000290 01 AFSTS1 PIC X(02). 000300* 000310 01 EFLAG PIC X(03). 000320* 000330 01 IN-P PIC X(01). 000340* 000350 SCREEN SECTION. 000360 SD GAMEN END STATUS IS ENDSTS. 000370 01 DSP-SUP. 000380** スクロール範囲2-24 上スクロールする 000390 05 LINE 1. 000400 10 COLUMN 1 PIC X(10) VALUE ""27C1"0224". 000410 10 COLUMN 1 PIC X(10) VALUE ""27C6"01". 000420 01 ACP-PAUSE. 000430 05 LINE 1. 000440 10 COLUMN 60 PIC X(01) USING IN-P. 000450 01 DSP-LINE. 000460 05 LINE 24. 000470 10 COLUMN 1 PIC X(80) FROM A1. 000480* 000490 PROCEDURE DIVISION. 000500************************************************ 000510** EFLAG = "LOP" .... READ NEXT DATA 000520** = "END" .... READ END 000530************************************************ 000540 MPROG. 000550 OPEN INPUT INFILE1 000560 MOVE "LOP" TO EFLAG. 000570 PERFORM UNTIL EFLAG = "END" 000580 READ INFILE1 000590 AT END 000600 MOVE "END" TO EFLAG 000610 NOT AT END 000620 DISPLAY DSP-SUP 000630 DISPLAY DSP-LINE 000640 END-READ 000650 END-PERFORM. 000660 CLOSE INFILE1 000670** 全部画面表示終わったら入力待ちする 000680 ACCEPT ACP-PAUSE. 000690 STOP RUN.
これがRDBに対応したプログラム。
000010 IDENTIFICATION DIVISION. 000020************************************************************ 000030** SAMPLE PROGRAM ** 000040** ファイルの内容を画面に出力する ** 000050************************************************************ 000060 PROGRAM-ID. YAMAGU. 000070* 000080 ENVIRONMENT DIVISION. 000090 INPUT-OUTPUT SECTION. 000100 FILE-CONTROL. 000110 SELECT INFILE1 ASSIGN TO FILE01-RDB 000120 ORGANIZATION IS SEQUENTIAL 000130 FILE STATUS WFSTS1. 000140 I-O-CONTROL. 000150 APPLY EXCLUSIVE-MODE ON INFILE1. 000160* 000170 DATA DIVISION. 000180 FILE SECTION. 000190 FD INFILE1 000200 BLOCK CONTAINS 256 CHARACTERS 000210 LABEL RECORD IS STANDARD 000220 VALUE OF IDENTIFICATION IS "FILE01". 000230 01 INREC. 000240 02 A1 PIC X(80). 000250 02 A2 PIC X(176). 000260* 000270 WORKING-STORAGE SECTION. 000280 01 WFSTS1 PIC X(02). 000290 01 AFSTS1 PIC X(02). 000300* 000310 01 EFLAG PIC X(03). 000320* 000330 01 IN-P PIC X(01). 000340* 000350 SCREEN SECTION. 000360 SD GAMEN END STATUS IS ENDSTS. 000370 01 DSP-SUP. 000380** スクロール範囲2-24 上スクロールする 000390 05 LINE 1. 000400 10 COLUMN 1 PIC X(10) VALUE ""27C1"0224". 000410 10 COLUMN 1 PIC X(10) VALUE ""27C6"01". 000420 01 ACP-PAUSE. 000430 05 LINE 1. 000440 10 COLUMN 60 PIC X(01) USING IN-P. 000450 01 DSP-LINE. 000460 05 LINE 24. 000470 10 COLUMN 1 PIC X(80) FROM A1. 000480* 000490 PROCEDURE DIVISION. 000500************************************************ 000510** EFLAG = "LOP" .... READ NEXT DATA 000520** = "END" .... READ END 000530************************************************ 000540 MPROG. 000550 OPEN INPUT INFILE1 000560 MOVE "LOP" TO EFLAG. 000570 PERFORM UNTIL EFLAG = "END" 000580 READ INFILE1 000590 AT END 000600 MOVE "END" TO EFLAG 000610 NOT AT END 000620 DISPLAY DSP-SUP 000630 DISPLAY DSP-LINE 000640 END-READ 000650 END-PERFORM. 000660 CLOSE INFILE1 000670** 全部画面表示終わったら入力待ちする 000680 ACCEPT ACP-PAUSE. 000690 STOP RUN.
恐ろしいくらい簡単です。
さらに、業務プログラムすらも修正する必要のない方法も用意されています。
ソースプログラムを失くしちゃった!とか、市販のパッケージソフトを購入したのでそもそもソースプログラムがない、ということもありますよね。このときはプログラムを修正できません。そのような場合はJCLの/ASSIGN文を使ってファイルからRDBに変更させることができます。例 (1) /ASSIGN ODEV=MSD000,DEV=MSD; ←デバイスアドレスの修正 /RUN PROG1; ←PROG1 の実行 /> ;[リレーショナル型データベース(2009年11月版)−第2部 設計編−第4章 RDBへの移行]より私の見たことのあるプログラムでは、たいていこのレベルで止まっているものが多いです。さらにSELECT/SCRATCHを使うプログラムに進化したり、トランザクション機能を使っているようなところは少ない印象です。
おそらく次のような理由ではないかと思います。1980年代頃に、経営者がどこからかデータベースの話を聞きつけ、「うちも最新のデータベースとやらを採用してみたい」→SEがデータをデータベースに移行してプログラムをMSDxxxからRDBに変更して「社長!御社も最新のデータベースシステムになりました!」のような感じではないかと。そして「最新」のデータベースシステムになったので、これ以上のデータベースの機能を必要と思わなかったのではないか。これは私の個人的な妄想です。
- 2 データの書き込み順と読み込み順
-
A−VX/RDBの物理ファイルの実体は複数索引順編成ファイルです。複数索引順編成の上に表定義というものを被せたものがA−VX/RDBになります。
このためA−VX/RDBの動きや保守の方法、特徴などに複数索引順編成の影が見ることがあります。
A−VX/RDBには面白い特徴があります。
よくOracleやSQL Server、MySQLなど一般的なRDB(以下オープン系RDBと書きますね)の入門書には 「データは追加した順に格納されているわけではない」 と書いてありますが、A−VX/RDBには当てはまりません。
A−VX/RDBは追加した順(発生順)にデータが格納されています。
そして表を順編成と指定して読み込むと、格納順でレコードを読み込みます。
また索引順編成と指定して読み込んだ場合も、同一キーのレコードは格納順で読み込まれます。
普通のデータベース(Oracle DBとかMySQLとか)の場合での動作と比較してみます。
普通のデータベースで、次のようにINSERTしたとします。insert into table1 values(3'りんご'); insert into table1 values(5,'みかん'); insert into table1 values(1,'ぶどう');
でselectしてみたとします。
select * from table1;
このとき、insertした順番で出力されるとは限りません。運よく、
3 りんご 5 みかん 1 ぶどう
と出るかもしれないし、
5 みかん 1 ぶどう 3 りんご
の順番で出力されるかもしれません。出力される順番は不定です。
これがA−VX/RDBでは異なります。
A−VX/RDBでは、表を順編成や相対編成でオープンしてREAD NEXTすると、格納順で出力されます。この特徴は重要で、A−VXの業務プログラムはこの特徴を利用して作られているものが多いです。
この特性を知らないまま、A−VX/RDBをそのままオープン系RDB(MySQLとかOracleDatabaseとかね)に持っていくと、「あれ?うまく動かない」とか「出力される順番が変わった」みたいなことが起きたりします。 - 3 ファイル編成別の順読みの差異について
-
ファイル編成のところで、「順編成と相対編成はデータファイルを直接アクセス、索引順編成はキーファイル経由でデータファイルをアクセスする」と書きました。ここでは、その点についてもう少し深く突っ込んでみようと思います。
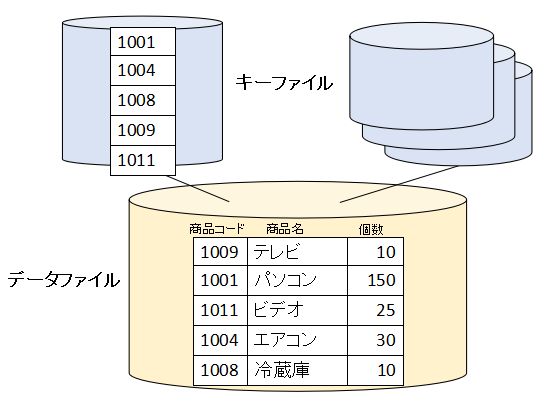
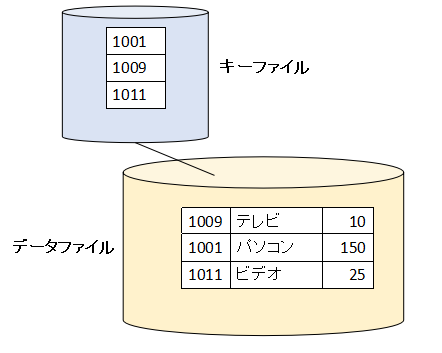
例えば、キーファイルとデータファイルに次のような情報が入っているRDBファイル(実体は複数索引順編成ファイル)があるとします。
1つ注目してほしいのは、データファイルは書き込みの順番でデータが入っており、キーファイルは昇順になっているという点です。
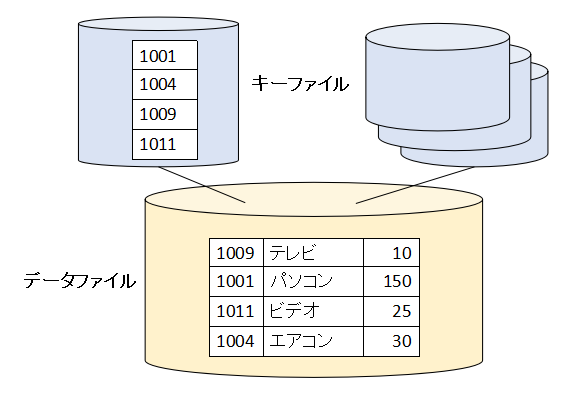
- 3.1 データファイル直接アクセスの場合
-
まず表を順編成か相対編成で扱う場合です。この場合はデータファイルを直接アクセスします。キーファイルがあっても直接は使いません。
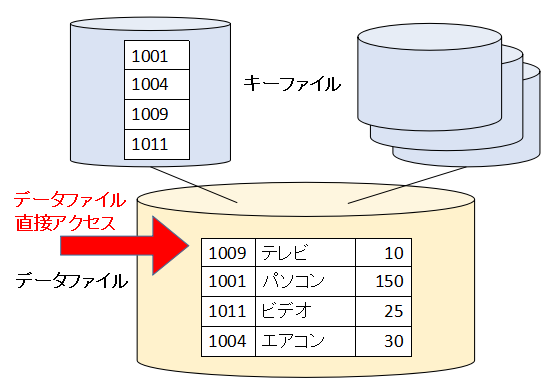
アクセスモードを順呼び出しにして、先頭のレコードから順番に読み込んでいきます。
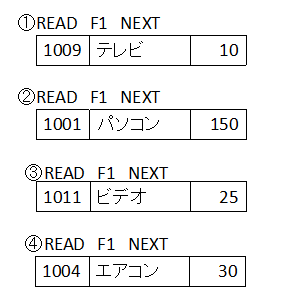
最初のREADでは、データファイルの一番先頭のレコード「1009:テレビ:10」というレコードを読み込みます。2回目のREADでは、次の「1001:パソコン:150」のレコードを読み込みます。3回目で「1011:ビデオ:25」、4回目で「1004:エアコン:30」のレコードを読み込み、次のREADでAT ENDになります。
このように、データファイルの先頭から順番にレコードを読み込んでいくことになります。データファイルのレコードの順番は書き込んだ順番なので、結局「データベースに書き込んだ順番」に読み込んでいくことになります。
- 3.2 キーファイル経由アクセスの場合
-
次は表を索引順で扱う場合です。この場合はキーファイル経由でデータをアクセスします。表を純粋にデータベースとして扱う場合もキーファイル経由でアクセスすることになります。
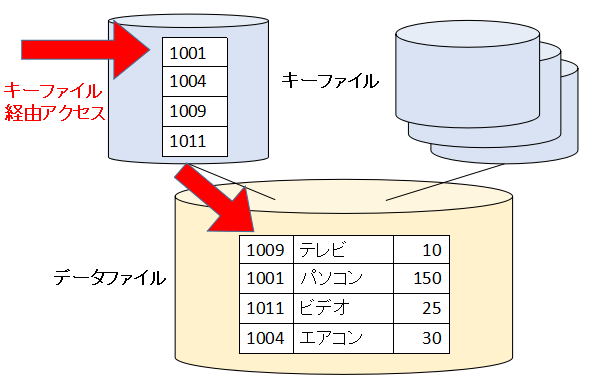
アクセスモードを順呼び出しにして、先頭から順番に読み込んでいきます。
最初のREADでは、キーファイルの先頭の「1001」を見て、キーが1001のレコード「1001:パソコン:150」を読み込みます。2回目のREADでは、キーファイルの次の「1004」を見て、「1004:エアコン:30」のレコードを読み込みます。同様に「1009:テレビ:10」、「1011:ビデオ:25」の順番で読み込んでいきます。
このようにキーファイルの順番にレコードを読み込んでいくことになります。キーファイルの順番は昇順なので、結局「キーの昇順」で読み込んでいくことになります。
さらにデータベースなのに、読み込む順番が決まっていることに注意が必要です。何度も書いていますが、一般のオープン系RDBは「order by asc/desc」のように順番を指定しない限り、出力される順番は不定ですが、A−VX/RDBは出力される順番が決まっているのです。
- 4 二重キーアクセスについて
-
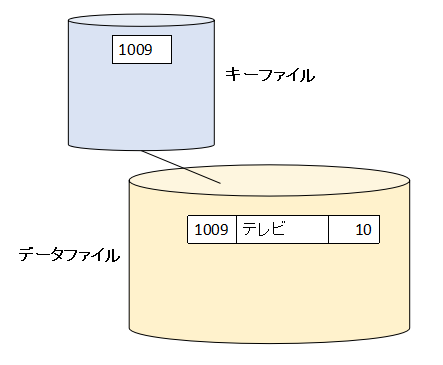
主キーはユニークである必要がありますが、それ以外のキーは「二重キーあり」の属性を付けることによって同じ値を持つようにすることもできます。 キーが「二重キーあり」のとき、キー読みして同じ値を持つキーがある場合のレコードを読み込む順番について考えてみます。
データベース上に上の図のようなデータがあるとします。
まずはオープン系RDBの場合を考えます。個数が10個のレコードを取り出そうとする場合、SQLだと次のようになると思います。select * from table1 where kosu = 10;
個数が10のレコードは2つあります。
このとき返ってくるレコードの順番は不定です。「1009 テレビ 10」「1008 冷蔵庫 10」の順番かもしれないしし、「1008 冷蔵庫 10」「1009 テレビ 10」の順番かもしれません。
次にA−VX/RDBの場合を考えます。
MOVE 10 TO KOSU. READ TABLE1 KEY IS KOSU ・・・
このとき返ってくるレコードの順番はデータファイルに格納されている順番です。まず「1009 テレビ 10」のレコードが読み込まれ、次にREADがあれば「1008 冷蔵庫 10」のレコードが読み込まれます。
このように一般的なオープン系RDBとA−VX/RDBで同一値を検索したときの結果に差異があります。A−VXのプログラムには二重キーありの場合の読み込み順が必ず決まっていることを前提にしたロジックで作られていることがときどきあったりします。そのようなプログラムを単純にLinuxやWindowsのオープンシステムに持っていくと、データベースの仕様差異で想定通りプログラムが動かない、ということがあったりします。
- 5 書き込みについて
-
念のためレコードを書き込んだ時にどうなるかも書いておきます。
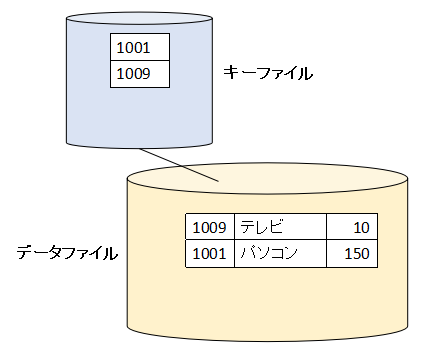
1つレコードが入っている状態から始めます。
「1001:パソコン:150」というレコードを書き込みます。データファイルの2レコード目にデータが書き込まれます。そしてキーファイルには昇順にキーの値が書き込まれます。
次に「1011:ビデオ:25」というレコードを書き込んだとします。データファイルの3レコード目にデータが書き込まれます。キーファイルには昇順にキーの値が書き込まれます。
次に「1004:エアコン:30」というレコードを書き込んだとします。データファイルの4レコード目にデータが書き込まれます。キーファイルには昇順にキーの値が書き込まれます。
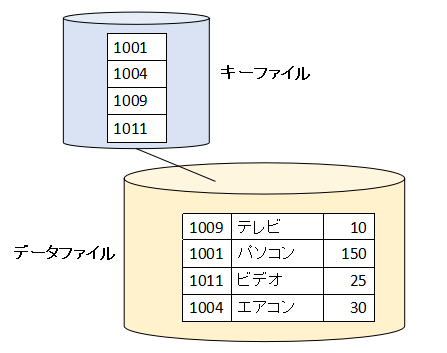
このようにデータファイルは書き込んだ順番、キーファイルには昇順にキーの値が書き込まれることになります。


