A−VXのファイル その2
NECのマニュアル「データ管理説明書」の補足をしようとする試みですが、データ管理説明書の最初の「第1章 基礎知識」のところは、今ではあたりまえなので書くものもないかと思ったのですが、書いておいた方が後で他の説明もしやすそうなので、下に簡単に説明しておきます。だいたいNECの公式のマニュアルに書いてあるのがすべてなので、そのマニュアルからの引用だけです。
- 1 フィールド
-
NECのマニュアルには次のような説明が書いてあります。
COBOLでいうとデータ項目に相当するものです。フィールドとは、データの論理的な最小単位であり、ユーザプログラムにおける最小の処理単位である。フィールドはデータ記述情報(例えば、COBOLのデータ部)の中で定義され、固有のフィールド名によって識別される。
「データ管理説明書(2009年11月版)」−「1.1 用語の定義」より - 2 レコード
-
同じくNECのマニュアルからの引用。
下の図の「顧客番号」「送状番号」「発注日付」「発送日付」「支払日付」がそれぞれフィールドで、それが集まったものがレコードです。レコードとは、上記フィールドの集まりであり、プログラムの論理的入出力(例えば,COBOLのREAD・WRITE命令)における単位である。
「データ管理説明書(2009年11月版)」−「1.1 用語の定義」より
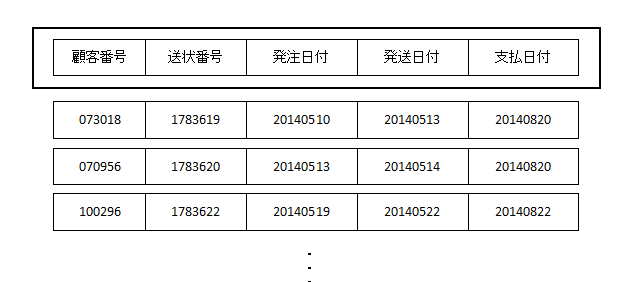 データベースを知っている人なら、データベースのテーブルと列の関係と同じものが、A−VXのファイルにもある(レコードとフィールド)ということが認識できるはずです。
データベースを知っている人なら、データベースのテーブルと列の関係と同じものが、A−VXのファイルにもある(レコードとフィールド)ということが認識できるはずです。
- 3 ブロック
-
これもNECのマニュアルからの引用。
ブロックとは,レコードの集まりであり,主記憶と二次記憶の間のデータの転送単位である。プログラムの入出力命令の単位がレコードという論理的なものであるのに対してブロックは物理的な単位であり、物理レコードともいわれる。1ブロックは1レコードあるいは2レコード以上で形成されるが、2レコード以上で形成することにより主記憶と二次記憶間のデータ転送回数を減らすことができる。
「データ管理説明書(2009年11月版)」−「1.1 用語の定義」より1レコード毎にハードディスクから読み込みしていると、10レコード読み込もうとすると10回、1万レコードを読み込もうとすると1万回ハードディスクから読み込まないといけないので非効率です。
そこで1回に複数レコードをまとめて読み込んで効率化を図ろういうことが考えられました。複数レコードを1つにまとめたものをブロックといいます。そしてブロック単位にハードディスクからメモリに転送を行います。ブロック単位でメモリに転送したブロックはいったんメモリ上に置いておき、プログラムの要求毎に1レコードづつプログラムに読み込まれます。
例えば10レコードを1ブロックにまとめれば10レコード読み込む場合もハードディスクからの転送は1回ですみます。ブロック単位でハードディスクから転送しても、プログラム側から見るとレコード単位で読み書きすることになるので、プログラム側は意識する必要はありません。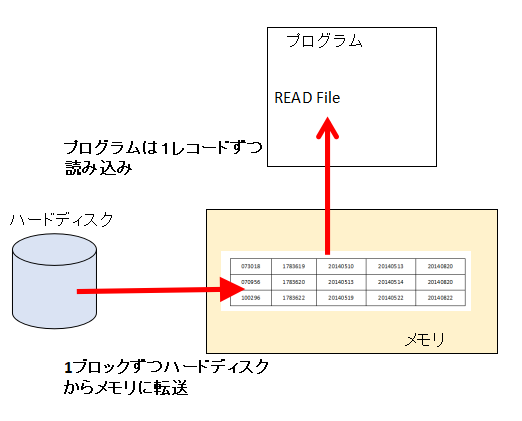
そうすると「1ブロックを1万レコードにまとめればいいのではないか」、という話も出てくると思います。ブロックをあまり大きなサイズにしてもメモリを消費するし、例えば保守などで1レコードだけ必要な時も1万レコードをメモリに転送しないといけないので、逆に効率が悪くなります。それ以前にブロックの最大サイズも決まっているので(最大で4096バイト)、実際はバランスを取って現実的な値にします。
下の表はファイル編成とブロック長およびレコード長の関係です。ファイル編成は後程説明します。
ファイル編成 磁気ディスク フロッピーディスク レコード長 ブロック長 レコード長 ブロック長 順編成 1〜4096 1〜4096 1〜1024 1〜1024 相対編成 1〜4096 1〜4096 1〜512 1〜512 索引順編成 5〜4096 5〜4096 5〜512 5〜512 複数索引順編成
(データファイル)5〜4096 5〜4096 − − ハードディスク(表の磁気ディスクのこと)で順編成ファイルを作るとき、レコード長の最大値は4096バイトです。ブロック長も4096バイトになります。つまり、レコード長を4096バイトにすると、1つのブロックに1つのレコードの構成になります。レコード長を128バイトにすると1つのブロックに最大32レコードまで構成することができます。
1ブロック最大256レコードまでという制約もあります。このため1バイトのレコードを4096個で1ブロックにするということもできません。
フロッピーディスクはハードディスクと比べて、レコード長やブロック長が小さいファイルしか作れません。
- 4 ファイル
-
またもやNECのマニュアルからの引用。
ファイルは論理的に関係のあるレコードの集まりであり,データ処理における最も基本的な単位である。例えば、送り状の1行を1フィールドとみなせば、完全な1枚の送り状は1レコードであり、さらにこのレコードの集まりがファイルである。
「データ管理説明書(2009年11月版)」−「1.1 用語の定義」よりファイルはWindowsやLinuxのファイルと同じ意味です。レコードが集まったものがファイルです。(0個のレコード=0バイトのファイルもあります。)
- 5 ボリューム
-
またもやNECのマニュアルからの引用。
ボリュームとは、取りはずしできる記憶装置の最小単位である。取りはずしできない二次記憶装置の場合は、その装置上の記憶装置をいう。例えば、一巻の磁気テープ、一台の固定ディスクなどをボリュームという。一つのボリューム上には1個のファイルのみを含む場合と2個以上のファイルを含む場合があり,磁気ディスク、フロッピィディスクおよび磁気テープにのみ一つのボリューム上に2個以上のファイルを含むことができる。
「データ管理説明書(2009年11月版)」−「1.1 用語の定義」よりA−VXのハードディスクのMSD000やMSD001などのようにMSDxxxがそれぞれ1つのボリュームです。ボリューム名というものがあって、ボリュームに名前が付けられます。例えばMSD000に「VOL1」とか「SAKURA」とか任意の名前が付けられます。
フロッピーディスクの1枚1枚がそれぞれが1つのボリュームです。フロッピーディスクのボリュームにもボリューム名が付けられます。
ボリューム名を付けて何が良いかというと、ユーティリティでチェックすることができることです。A−VXのユーティリティは何かボリュームに対して操作するとき、装置名とボリューム名をきいてきます。装置名かボリューム名のどちらかは省略できますが、両方入力することによって間違いを防ぐことができます。
例えば2台のオフコンがあって、オフコンAのMSD000のボリューム名が「sakura」、オフコンBのMSD000のボリューム名が「fuji」とします。#ABCでボリュームを初期化するときにMSD000だけ入力してボリューム名を省略することができますが、このときオフコンBのMSD000を初期化するつもりで間違ってオフコンA上で操作してしまうとボリューム名を省略しているので、そのままオフコンAのMSD000を初期化してしまいます。一方、ボリューム名も入力するようにすれば「fuji」と「sakura」と異なるので、ユーティリティがエラーを出して、気が付くことができます。ハードディスクもフロッピーディスクも1つのボリュームに複数のファイルを作ることができます。これはWindowsも同じですよね。WindowsはCドライブに沢山のファイルを作ることができます。
フロッピーディスクは複数のボリュームに1つのファイルを入れることもできます。フロッピーディスクは1枚の容量が1.2メガバイトしかないので、5メガバイトとか10メガバイトのファイルは入りません。この時は複数のフロッピーディスク(つまり複数のボリューム)を使って、1つのファイルを入れることになります。これをマルチボリュームファイル(複数ボリュームファイル)といいます。
1つのボリュームだけに入っているファイルをシングルボリュームファイルといいます。 - 6 セクタ
-
ハードディスクやフロッピーディスクなどはセクタという単位で区切られて管理されています。
今は、1セクタは256バイトです。
NECの説明書には1セクタが何バイトなのかあまり明確に書いていないようです。(昔は1セクタ128バイトとか、1セクタがいろいろなハードディスクやフロッピーディスクがあったため、説明書には明確に書かれていないようです。要は説明書では書けないので、それぞれのハードディスクの仕様を見てくれということ。)
ブロックのところでは、レコードとブロックの関係について説明しましたが、ここではセクタとレコード、ブロックの関係について説明してみます。
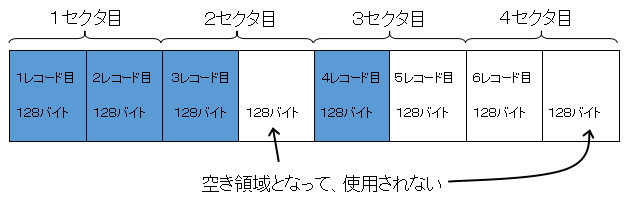
ここで、あるデータファイルに128バイトのデータ(レコード)を4件格納するとします。まずはブロック化しない場合を考えてみます。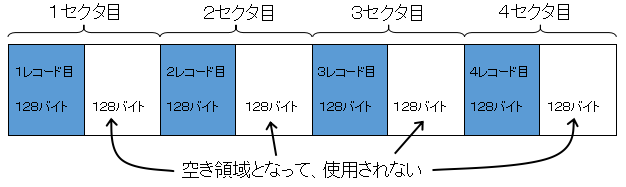
上の図のように、1セクタに1レコードずつしか格納されず、4件格納するのに4セクタ必要になります。1セクタごとに128バイトの空き領域ができて、利用効率が悪いです。
そこで、ブロック化してレコードを格納することにします。2つのレコードを1つのブロックとして扱い、格納することにします。
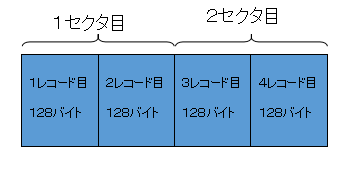
このようにすると空き領域が無くなり、2セクタで4件のレコードが格納できるようになり、効率がよくなります。1ブロック中のレコードの数をブロック化係数といい、今回の場合はブロック化係数が2ということになります。また、レコード長×ブロック化係数をブロック長といい、今回のブロック長は256となります。
ブロック長は最大で4096バイトとなります。さて、ここでブロック化係数を3にするとどうなるかです。
1ブロックに2セクタ使用しますが、2セクタ毎に128バイト空き領域ができます。ブロック化係数を4にすると、またピッタリになります。
レコード長が128バイトの場合は、ブロック化係数が2,4,6,8・・のときに効率が良さそうです。そうなると、2,4,6,8・・・のどれがいいか?ですが、そこはブロックのところで説明した通り、メモリに転送する回数で考えます。順アクセスする場合は、1回に読み込むデータを多くした方がよいので、なるべくブロック化係数を大きな値にします。ランダムアクセスなら、1回にあまりたくさん読み込んでも効率が悪いので、ブロック化係数は2ぐらいでいいかもしれません。
今までは、1レコード128バイトというキリの良い数値でしたが、一般的には1レコード200バイトとか316バイトとか、いろいろなレコード長です。
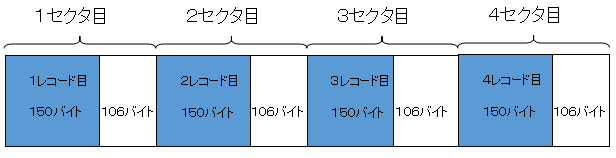
例えば、1レコード150バイト、ブロック化係数1の場合は下の図のようになります。
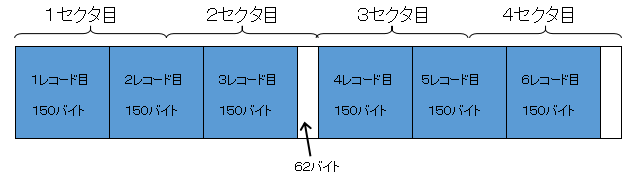
1レコード150バイト、ブロック化係数3の場合。
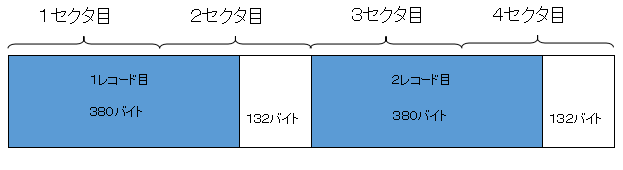
1レコード380バイト、ブロック化係数1の場合。
セクタ、レコード、ブロックの関係から、ブロック化係数は次のように決めます。
- データの格納効率を考えて、なるべくブロック長が256バイトの倍数か、それより少し少ない長さにする
- データのアクセス効率を考えて、順アクセスの場合はなるべくブロック化係数は大きな数値にする、ランダムアクセスの場合はなるべく少ない値にする
- ブロックの最大長は4096バイト、1ブロック最大256レコードまでという制限があるので、その範囲内で


